
Running Large Language Models on your machine can enhance your projects, but the setup is often complex. Ollama simplifies this by packaging everything needed to run an Large Language Models. Here’s a concise guide on using Ollama to run LLMs locally.
Requirements
- CPU: Aim for an CPU that supports AVX512, which accelerates the matrix multiplication operations essential for LLM AI models. (If your CPU does not support AVX, see Ollama Issue #2187: Support GPU runners on CPUs without AVX.)
- RAM: A minimum of 16GB is recommended for a decent experience when running models with 7 billion parameters.
- Disk Space: A practical minimum of 40GB of disk space is advisable.
- GPU: While a GPU is not mandatory, it is recommended for enhanced performance in model inference. Refer to the list of GPUs that are compatible with Ollama. For running quantized models, GPUs that support 4-bit quantized formats can handle large models more efficiently, with VRAM requirements as follows: ~4 GB VRAM for 7B model, ~8 GB VRAM for 13B model, ~16 GB VRAM 30B model, and ~32 GB VRAM for 65B model.
- For NVIDIA GPUs: Ollama requires CUDA, a parallel computing platform and API developed by NVIDIA. You can find the instructions to install CUDA on Debian here. Similar instructions can be found in your Linux distribution’s wiki.
Step 1: Install Ollama
Download and install Ollama for Linux using:
curl -fsSL https://ollama.com/install.sh | shCode language: plaintext (plaintext)Step 2: Download a Large Language Model
Download a specific large language model using the Ollama command:
ollama pull gemma2:2bCode language: plaintext (plaintext)The command above downloads the Gemma2 model by Google DeepMind. You can find other models by visiting the Ollama Library.
(Downloading “gemma2:2b” actually downloads “gemma2:2b-instruct-q4_0”, indicating that it retrieves a quantized version of the 2 billion parameter model specifically optimized for instruction-following tasks like chat-bots. This quantization process reduces the model’s precision from the original floating-point representation to a more compact format, such as float32, thereby significantly lowering memory usage and enhancing inference speed. However, this quantization can lead to a slight decrease in accuracy compared to the full-precision floating-point model.)
Step 3: Chat with the model
Run the large language model:
ollama run gemma2:2bCode language: plaintext (plaintext)This launches an interactive REPL where you can interact with the model.
Step 4: Install open-webui (web interface)
Open-webui offers a user-friendly interface for interacting with large language models downloaded via Ollama. It enables users to run and customize models without requiring extensive programming knowledge.
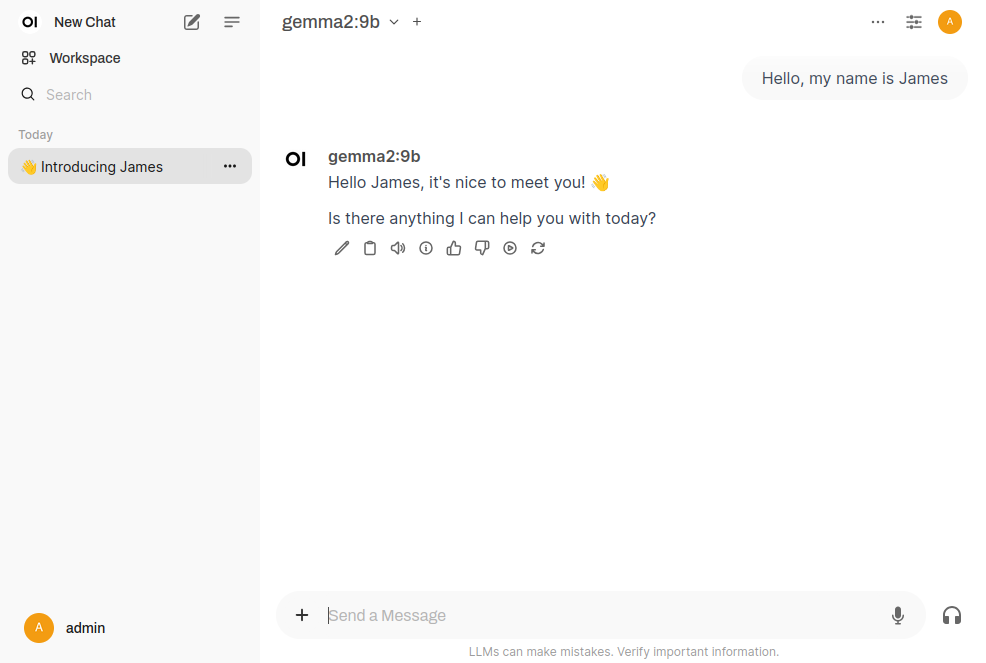
It can be installed using pip within a Python virtual environment:
mkdir -p ~/.python-venv/open-webui
python -m venv ~/.python-venv/open-webui
source ~/.python-venv/open-webui/bin/activate
pip install open-webuiCode language: plaintext (plaintext)Finally, execute the following command to start the open-webui server:
~/.python-venv/open-webui/bin/open-webui serveCode language: plaintext (plaintext)You will also have to execute Ollama as a server simultaneously with open-webui:
ollama serveConclusion
With Ollama, you can quickly run Large Language Models (LLMs) locally and integrate them into your projects. Additionally, open-webui provides a user-friendly interface for interacting with these models, making it easier to customize and deploy them without extensive programming knowledge.
Links
- Ollama Library: A collection of language models available for download through Ollama.
- Ollama @Github: The Ollama Git repository.
- Compile Ollama: For users who prefer to compile Ollama instead of using the binary.

